연관규칙분석이란?
연관 규칙 분석이란 어떤 두 아이템 집합이 번번히 발생하는가를 알려주는 일련의 규칙들을 생성하는 알고리즘입니다. 경영학에서 장바구니 분석(Market Basket Analysis)으로 알려진 이 알고리즘은 누구나 한 번쯤 경험해보았을 것입니다. 오늘은 최근 인터넷 쇼핑 및 상품 진열 등 다양한 컨텐츠 기반 추천(contents-based recommendation)에 널리 사용되고 있는 이 연관규칙분석 알고리즘에 대해 알아보고자 합니다.
사실 상품 추천에는 순차분석 (Sequence Analysis), Collaborative Filtering , Contents-based recommendation 등 여러가지 분석 기법이 존재합니다. 그 중 하나가 바로 연관규칙분석입니다. 연관규칙분석은 거래(transaction)와 항목(item)으로 구성되어 있는 경우 분석이 가능합니다.
- 연관규칙분석, 장바구니분석 (Association Rule Analysis, Market Basket Analysis) : 고객의 대규모 거래데이터로부터 함께 구매가 발생하는 규칙(예: A à 동시에 B)을 도출하여, 고객이 특정 상품 구매 시 이와 연관성 높은 상품을 추천
- 순차분석 (Sequence Analysis) : 고객의 시간의 흐름에 따른 구매 패턴(A à 일정 시간 후 B)을 도출하여, 고객이 특정 상품 구매 시 일정 시간 후 적시에 상품 추천
- Collaborative Filtering : 모든 고객의 상품 구매 이력을 수치화하고, 추천 대상이 되는 고객A와 다른 고객B에 대해 상관계수를 비교해서, 서로 높은 상관이 인정되는 경우 고객B가 구입 완료한 상품 중에 고객A가 미구입한 상품을 고객A에게 추천
- Contents-based recommendation : 고객이 과거에 구매했던 상품들의 속성과 유사한 다른 상품 아이템 중 미구매 상품을 추천 (↔ Collaborative Filtering은 유사 고객을 찾는 것과 비교됨)
- Who-Which modeling : 특정 상품(군)을 추천하는 모형을 개발 (예: 신형 G5 핸드폰 추천 스코어모형)하여 구매 가능성 높은(예: 스코어 High) 고객(군) 대상 상품 추천
연관규칙분석에서 규칙의 효용성
연관규칙분석은 이름에서 의미하는 그대로 규칙 베이스로 합니다. 여기서 예시를 한 번 봅시다.
dataset=[['사과','치즈','생수'],
['생수','호두','치즈','고등어'],
['수박','사과','생수'],
['생수','호두','치즈','옥수수']]
위와 같은 데이터 셋이 있을 때,
1 : (사과,치즈.생수)
2: (생수,호두,치즈,고등어)
3: (수박,사과,생수)
4: (생수,호두,치즈,옥수수)
규칙
- 사과를 산 사람은 생수를 산다.
- 생수를 산 사람은 고등어를 산다.
- 치즈를 산 사람 생수를 산다.
...
등등 엄청나게 많은 규칙들을 생성할 수 있습니다. 그렇다면 어떤 규칙이 좋은 규칙인지 어떻게 판단할 수 있을까요?
좋은 규칙을 판단하는 세가지 지표가 있습니다.
- 지지도(support) : 한 거래 항목 안에 A와 B를 동시에 포함하는 거래의 비율. 지지도는 A와 B가 함께 등장할 확률이다. 전체 거래의 수를 A와 B가 동시에 포함된 거래수를 나눠주면 구할 수 있다.
- 신뢰도(confidence) : 항목 A가 포함하는 거래에 A와 B가 같이포함될 확률. 신뢰도는 조건부 확률과 유사하다. A가 일어났을 때 B의 확률이다. A의 확률을 A와 B가 동시에 포함될 확률을 나눠주면 구할 수 있다.
- 향상도(lift) : A가 주어지지 않을 때의 품목 B의 확률에 비해 A가 주어졌을 때 품목 B의 증가 비율. B의 확률이 A가 일어났을 때 B의 확률을 나눴을 때 구할 수 있다. lift 값은 1이면 서로 독립적인 관계이며1보다 크면 두 품목이 서로 양의 상관관계, 1보다 작으면 두 품목이 서로 음의 상관관계이다. A와 B가 독립이면 분모, 분자가 같기 때문에 1이 나온다.
연관규칙분석 알고리즘
연관규칙분석의 대표적인 알고리즘은 3가지로 분류할 수 있습니다. 하지만 저는 가장 많이 쓰이고 예제도 많은 Apiori 알고리즘에 대해서만 다루려고 합니다. Apiori 알고리즘이 널리 쓰이는 이유는 알고리즘 구현이 비교적 간단하고 높은 수준의 성능을 보이기 때문입니다.
1. Apriori algorithm
2. FP-Growth algorithm
3. DHP algorithm
Example) 장바구니 분석
사실 지금까지는 Apriori 알고리즘을 왜 사용해야하는지 그 개념이 무엇인지를 알기 위한 과정이였습니다. 대략적인 과정을 알았으니 간단한 예제를 통해 어떻게 활용할 수 있을지 알아봅시다.
1. 필요한 모듈 import
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
- pandas : 파이썬에서 사용하는 데이터분석 라이브러리로, 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있게 되며 보다 안정적으로 대용량의 데이터들을 처리하는데 매우 편리한 도구
- mlxtend : 일상적인 데이터 사이언스 작업에 유용한 도구들로 구성된 파이썬 라이브러리
2. 데이터 셋 생성 및 가공
dataset = [['Milk', 'Onion', 'Nutmeg', 'Eggs', 'Yogurt'],
['Onion', 'Nutmeg', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Eggs'],
['Milk', 'Unicorn', 'Corn', 'Yogurt'],
['Corn', 'Onion', 'Onion', 'Ice cream', 'Eggs']]
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
데이터 셋 생성과정은 문제 없이 이해할 수있을 것 입니다. 마지막 두 줄에 대해서만 따로 알아봅시다.
주어진 코드에서 fit 함수를 통해 dataset은 고유한 라벨을 갖게 되고 , transform함수를 통해서 파이썬 리스트를 one-hot 인코딩 된 numPy 배열로 변환합니다. one-hot 인코딩에 대한 자세한 설명을 원하시면 다음 글을 참고해 주시기 바랍니다. ( https://teddylee777.github.io/machine-learning/python-numpy%EB%A1%9C-one-hot-encoding-%EC%89%BD%EA%B2%8C%ED%95%98%EA%B8%B0 )
배열을 출력해 보면 다음과 같이 확인 할 수 있습니다. 즉, 이 과정을 거치면 (Apple, Corn, Eggs, Ice cream, Milk, Nutmeg, Onion, Unicorn, Yogurt) 을 컬럼으로 갖고 아이템의 유무에 따라 True, false로 표현 된 배열을 갖게 됩니다.

3. Apriori 알고리즘 활용
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
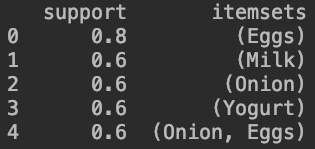
우리는 Apriori 알고리즘을 활용하여 지지도가 0.5 이상인 것들을 알아낼 수있습니다.
dataset =
[['Milk', 'Onion', 'Nutmeg', 'Eggs', 'Yogurt'],
['Onion', 'Nutmeg', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Eggs'],
['Milk', 'Unicorn', 'Corn', 'Yogurt'],
['Corn', 'Onion', 'Onion', 'Ice cream', 'Eggs']]
즉, 5개의 장바구니 중에 Eggs는 4개에 들어가 있으므로 80%의 확률을 갖는다고 할 수 있습니다.
association_rules(frequent_itemsets, metric="lift", min_threshold=1)association_rules 함수를 이용하여 지지도가 0.5가 넘는 항목에 대해 향상도가 양의 상관관계에 있는 것이 무엇인지 알아봅시다.

여기서는 egg와 Onion이 양의 상관관계가 있는 것으로 확인 되네요.
Reference
- https://rfriend.tistory.com/190
- https://ratsgo.github.io/machine%20learning/2017/04/08/apriori/
- https://ordo.tistory.com/89?category=751589
- https://blog.naver.com/eqfq1/221444712369
- https://jfun.tistory.com/104
- https://doorbw.tistory.com/172
-http://rasbt.github.io/mlxtend/
'Programming > PYTHON' 카테고리의 다른 글
| [python] from, import, as 사용법 (5) | 2020.02.08 |
|---|---|
| [python] 리스트(List), 튜플(Tuple), 딕셔너리(Dictionary), 집합(Set) (0) | 2020.02.08 |
댓글